

据说GPT-4下周就要出场了,并且OpenAI已经在3.8发布了一篇大炸弹做预热了,那么连同这篇文章让我么来看看最近多模态大模型有什么新的进展吧。
0.先介绍概念
简要介绍一下吧,主要是相比于神经网络前沿,这个栏目(计划是)更加闲谈一些。
首先是大模型,其实很简单,就是规模非常大的模型,据说新的标准下一千亿以上的参数才能称自己是大语言模型了。
现在最大的模型参数量应该是还不足2T(两万亿)的,并且超过1T的模型基本都是MoE了,实际运行的参数还远没有那么大。所以之前网传的GPT-4将有100万亿应该是谣言(小导师告诉我们的,我就信了,其实最近相关论文读的多了,也觉得不要太可能,主要是一下提升太多,除非真的是什么硬件上的超级黑科技)。
但多模态应该是没跑了,毕竟KOSMOS-1已经表明微软已经和OpenAI在微调一些多模态大模型了。
多模态简单来说就是你既可以输入文字又可以输入图片、视频啥的。大家知道ChatGPT目前输入只支持文字,是个比较纯正的语言大模型,你不能放张图片进去问它这是什么动物的。多模态就是试图解决这个问题。
上面出现的一些词汇(MoE、多模态等)可以在我以往的一些专栏中找到,稍微放几个链接:
【花师小哲】当代炼金术(神经网络)前沿(18)——多模态思维链战胜大模型?
【花师小哲】当代炼金术(神经网络)前沿(16)——语言模型的其他出路
ok,下面就来介绍几个多模态大模型吧。
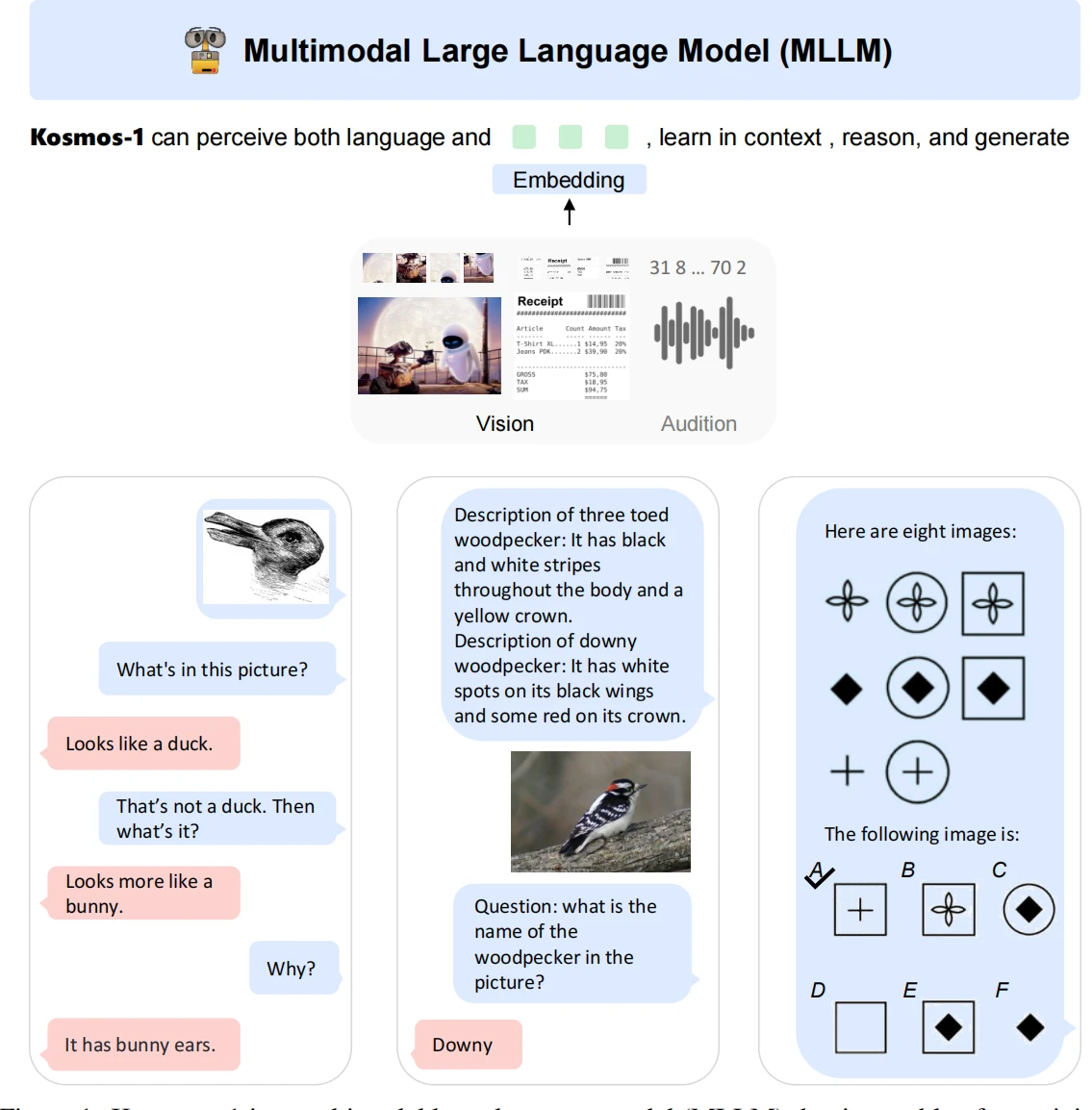
1.KOSMOS-1
直接就叫自己的模型宇宙1号,可见微软对这个模型还是比较满意的。
不过很明显,这个模型是完全基于大语言模型主体的,实际上它是将其他模态想办法转变成能够适应大语言模型输入的形式的。
或者说,对于KOSMOS-1来说,其实输入也只是语言,只不过多了一些叫做“图片”“声音”这样的外语罢了。或许正如文章所引用的名言:“The limits of my language means the limits of my world.Ludwig Wittgenstein”(维特根斯坦厨狂喜好吧,就不翻译了,真有不懂得朋友可以去查,这里就神秘一些[?])
2.PaLM-E
谷歌当然也不会放过这个机会,也推出了PaLM-E,而且看起来甚至更强一些。
毕竟在OpenAI推出1750亿的大模型GPT-3之后,谷歌也搞出了5400亿的大模型PaLM。PaLM-E其实就是PaLM+220亿的ViT(一个视觉大模型)。
可见,PaLM-E是真的做了多模态融合的,而且参数量也非常恐怖(5620亿)了,不过,主体依然是语言大模型。
除了语言和视觉模态外,输入还可以是状态模态,这意味着,PaLM-E是可以做机器人控制的,而且可能还是主要“炫技”方向。
对于一个机器人,我们可以通过一条命令(例如“帮我去找到某个抽屉里的一包薯片”)来让机器人仅仅依靠视觉信息自行完成走路、翻不同的抽屉、识别哪包零食是薯片、取出、送回等一系列操作的。
如果说ChatGPT是一个面向“开放域”问答(就是你可以问它任何领域的问题,不需要局限在例如医学等领域)的AI的话,PaLM-E是可以面向“开放域”决策的(可能这时候很多自媒体就说终结者来了啥的)。
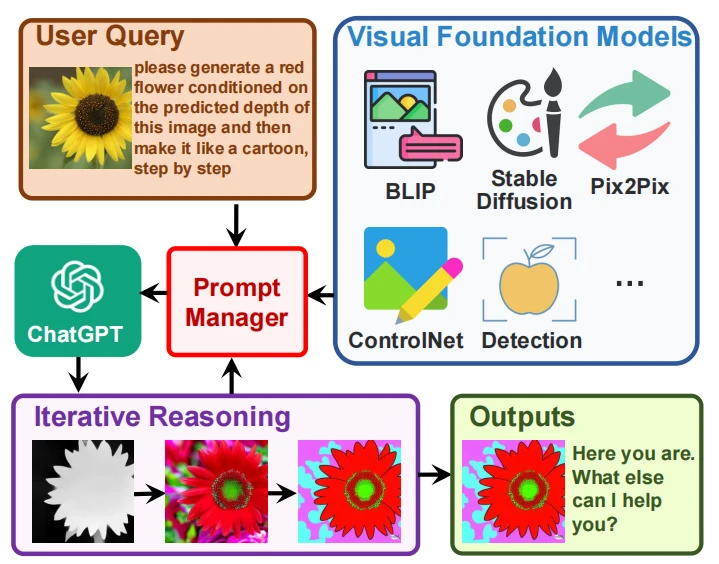
3.Visual ChatGPT
开篇提到的论文。其实看名字就理解的八九不离十了,没错,依然是让语言模型当绝对C位,其它模态其实是为了语言模型服务的。只不过这里的语言模型是ChatGPT而已。
从图片就更明显了,ChatGPT的核心其实基本没动,就是往外加配件(包括Stable Diffusion,还有很多比较平常的工具,例如滤镜、PS啥的)。关于大模型使用工具的论文也有介绍过,这里也不多展开:
其实从想法上这个论文其实没有太创新的地方(当然工程上难度还是有的),不过有ChatGPT热度加持,还是让人有兴趣研究的。而且好像是微软亚洲研究院做的,作者好像都是中国人或华人。
这个模型最难的部分当然就是那个prompt manager了,里面还是很复杂的,即如何协调输入、工具、历史信息等。毕竟,Visual ChatGPT也是要记住历史信息的(硬性记住),例如可以对一张图片做很多不同的处理(加滤镜等)。你可以认为是个懒人PhotoShop。
那么GPT-4性能究竟会如何呢?没办法,继续等呗。


「艾尔登法环」梅琳娜手办开订 立体手办▪

万代「艾尔登法环」白狼战鬼手办开订 立体手办▪

「夏目友人帐」猫咪老师粘土人开订 立体手办▪

「五等分的新娘∬」中野三玖·白无垢版手办开订 立体手办▪

「海贼王」乌索普Q版手办开订 立体手办▪

良笑社「初音未来」新手办开订 立体手办▪

「黑岩射手DAWN FALL」死亡主宰手办开订 立体手办▪

「盾之勇者成名录」菲洛手办登场 立体手办▪

「魔法少女小圆」美树沙耶香手办开订 立体手办▪

「咒术回战」七海建人粘土人登场 立体手办▪

「五等分的新娘」中野二乃白无垢手办开订 立体手办▪

「为美好的世界献上祝福!」芸芸粘土人开订 立体手办▪

「公主连结 与你重逢」六星可可萝手办开订 立体手办▪


「女神异闻录5」Joker雨宫莲手办开订 立体手办▪

「间谍过家家」约尔・福杰粘土人登场 立体手办▪


「街角魔族 2丁目」吉田优子手办开订 立体手办▪

「火影忍者 疾风传」旗木卡卡西·暗部版粘土人登场 立体手办▪

「佐佐木与宫野」宫野由美粘土人开订 立体手办▪

「盾之勇者成名录」第2季拉芙塔莉雅手办开订 立体手办▪

「咒术回战」两面宿傩Q版坐姿手办开订 立体手办▪

「DATE·A·BULLET」时崎狂三手办开订 立体手办▪

「狂赌之渊××」早乙女芽亚里粘土人开订 立体手办▪

「魔道祖师」魏无羨粘土人开订 立体手办▪

「新·奥特曼」奥特曼手办现已开订 立体手办▪












































 扫码关注我们
扫码关注我们